前段时间看了别人的一个写了羊了个羊刷次数网页版,但是 js 代码做了混淆,然后我的那个解混淆的工具还没适配上,短时间内还原不了。但由于是网页版,所以抓包数据还是能看到的,于是就准备复刻了一个。
可在此体验:7y8y.vercel.app (当然由于官方改动,现在功能已经失效了,但看看页面到不成问题,可能需要科学上网)
原本我是不考虑写的,但是这背后所涉及到的技术以及技术框架我是特别想聊聊,加之以后我也有很大的可能会再写一个类似的刷 xx 的网页版,所以就考虑写一个类似的模板以便后续应用需求。
与此同时,我也快有半年的时间没碰 协议复现(网络通信协议重新实现,后文都简称协议复现)。我更喜欢说这个词,也有的人会说模拟请求,对应的关键词可能有 post 请求,抓包,发包,爬虫等等,但大致的意思是抓取请求数据包,然后脱离宿主机(浏览器,手机),将抓取的数据包重新发送一遍。
你也可以理解成爬虫,但和爬虫相比,要做的不只是爬取数据,而是要基于某些请求包(或者说调用他人不提供的 api 接口,即爬取),来实现一定的功能。比如登录协议,签到协议,抢购协议,游戏封包等等,然后不依靠宿主机(即不用登录浏览器或者应用设备)就能实现诸如登录,签到等功能(在后台记录是有的)。因为这些都是基于网络通信协议的,只要抓包(抓取数据包),然后使用编程提供的网络请求模块来模拟请求,达到重新发包,重新请求的目的。在网页中有 http 协议,websocket 协议,而游戏中有相应的与游戏服务器对应的协议,邮件短信文件又是不同的协议(这里的协议都叫网络通信协议),所以我个人更倾向于称之为协议复现。
所以要做协议复现,那基本上有一定的逆向功底和爬虫能力,还有网络通信协议相关的知识了。此次的开发也算是回顾下这些相关技术了。
小区开门应用
在这里容我多废话几句,讲一个我之前的一次开发经历,可以说这次的开发经历算是这篇文章的由来。
应用需求
在之前住的一个小区,有个门禁系统,需要安装一个开门的 app(后文都称开门 app),然后注册一个账号到物业那边登记为户主或家庭成员。
每次开门的时候,都需要打开这个开门 app,然后点击你要打开的门,接着门就打开了。或者叫保安开个门,总之就是特别麻烦,还不提供创建应用快捷方式。
于是我想的是将接口数据“偷”了过来,将大门列表展示在前端上,然后点击对应的大门,然后将大门 id 转发给原 app 的服务器,就实现了开门的效果,也就是这个小区开门的网页版的核心逻辑。
当时设计的界面大致如下,展示小区的大门,点击即可远程开门。
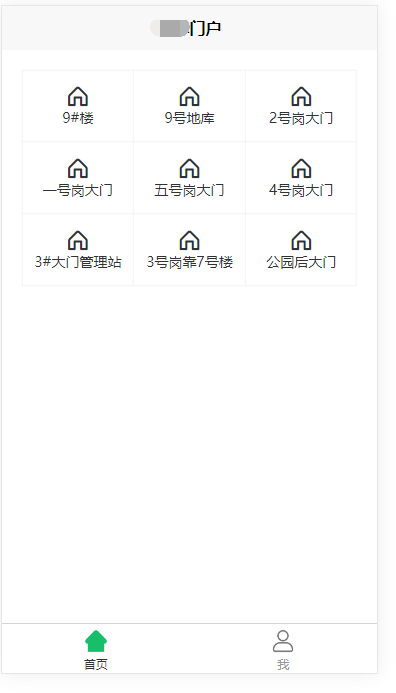
因为是网页版的,所以只需要在浏览器打开对应的网址,点击对应的大门按钮即可。而开发的初衷是这个 app 不提供桌面快捷方式,点击这个 app 还需要观看首屏广告,此外他人也不用到物业登记,就能开门,对于一些朋友或者住户来说,省去了物业登记的繁琐。
不过这个软件还是有挺多要注意的点:首先就是鉴权了,由于我当时主要目的是为了我自己和身边朋友,网站也没有特意发布到互联网上,所以就没做鉴权相关的,不然正常情况下是一定要做鉴权和调用记录的,以及 ip 白名单的。否则搞不好登录原 app 的账号直接因为调用过于频繁直接给禁用了;最主要的安全问题,这里的安全可不只是网站的安全,而是现实的安全。想想如果有一个可以随意进出小区大门的程序,那么任何人都可以进入这个小区,小区的公共设施,业主生活质量安全等等谁来保障?而且最主要所绑定的账号还是我的,万一小区真出了事,那么我的责任将会非常大。
综合考量,这个应用是绝对不可能大肆发布到网上的。个人自用问题还是不大,因为这种调用量对服务器几乎没有什么压力。
在当时我甚至想基于手机的 GPS 定位,来实现靠近小区自动开门。真羡慕当时我的一堆想法,但也遗憾当时没有去尝试实现这一个想法。
开发
这个应用的起源就说到这了,接下来我要说说其开发形态了,这也就是本文说要的重点内容了。下面是我当时的项目结构:
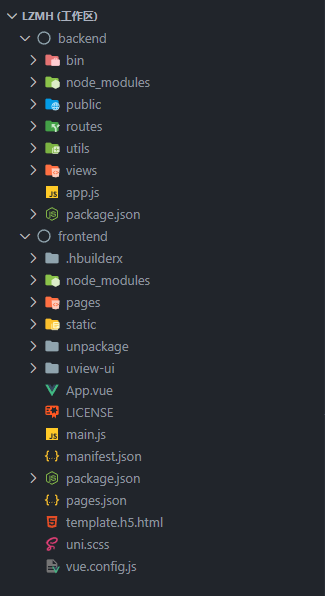
不难看出,这是一个前后端分离的项目,其中前端使用 uniapp 来开发一套代码多端运行,并且使用的是 Hbuilder 编辑器来开发。而后端就是常规的 Node 后端服务,使用的是 Express 框架。
技术栈就介绍完毕,这里我要介绍整个开门实现流程。
就说说获取大门列表和开门的两个接口请求:
获取大门列表
后端接口:http://localhost:3000/api/list
这个接口主要的作用就是获取原开门 app 的大门列表,这里简单介绍下代码
router.get('/list', async (req, res, next) => {
// 模拟请求获取所有大门数据
let url = `https://xxx.com/api/getDoorList`
let data = {
xxx: {},
}
let json = await (await axios.post(url, data)).data
return json // [{...},{...},{...}]
})
然后前端请求后,将列表数据渲染到页面上。
开门请求
后端接口:http://localhost:3000/api/open
router.get('/open', async (req, res, next) => {
let { id } = req.query
// 模拟请求开门
let url = `https://xxx.com/api/openDoorControl`
let data = {
id: id,
}
let json = await (await axios.post(url, data)).data
return json // { "code": 0 ,"msg": "success" }
})
这里的代码也仅仅只是作为演示,实际代码可不止这么简单,因为还需要涉及到登录,加密等等环节。
我的前端页面访问地址是 http://localhost:5000,我需要访问后端接口 http://localhost:3000/api/list 和 http://localhost:3000/api/openDoor。
对于不了解 web 开发的人员可能会问为啥要后端服务,不直接在前端向开门 app 的服务器发送请求,然后将响应直接渲染到前端上。比如直接在前端代码中写 openopenDoor 函数
async function openDoor(id) {
// 模拟请求开门
let url = `https://xxx.com/api/openDoorControl`
let data = {
id: id
}
let json = await (await axios.post(url, data)).data
return json // { "code": 0 ,"msg": "success" }
})
这个疑惑在我初次想使用 web 端来实现协议复现的时候也考虑过,但浏览器为了安全考虑而不支持。这也是我下面所要说的
同源策略 跨域
一般用户的浏览器是有非常强的页面安全策略的,这里要说的就是同源策略,更细分点就是跨域。比如说 kuizuo.cn 这个站点,想要向 baidu.com 发送请求,请求是能够正常发送过去的,但是 kuizuo.cn 这个站点是接收不到任何数据。因为 kuizuo.cn 和 baidu.com 根本不��是同一个网址,专业点说就是不同源,这种不同源的请求在浏览器,称为跨域请求。

跨域请求如果请求的服务端不允许跨域,即响应协议头没有如下内容
access-control-allow-credentials: true
access-control-allow-headers: Content-Type, Authorization, X-Requested-With
access-control-allow-methods: GET, POST, PUT, DELETE, OPTIONS
access-control-allow-origin: *
浏览器会直接拒绝接收响应,但浏览器确实将请求发送给了服务端,并且你打开控制台中的网��络是看不到该请求的响应结果的。
跨域限制只存在于浏览器端,在其他环境下是不存在,请求都是能够发送出去,并且是可以接收到的。所以说为什么不在前端直接向原应用程序的服务器发送请求,罪魁祸首也就是同源策略。
不支持修改协议头
像 origin,reference,user-agents 等协议头在浏览器是无法修改的
origin: https://xxx.com
referer: https://xxx.com/api/test
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42
而有些请求是会效验你的设备信息,来源地址,这些内容在浏览器中都写在协议头中,且浏览器不支持修改。使用浏览器来发送数据,无疑就是告诉服务器我是浏览器发送的。服务器判断来源不是自家的域名,那就直接拒绝响应,像防盗链就是检测 referer 。
方案
桌面端应用开发
正是因为同源策略的限制,导致做协议复现时往往都会选择在本地中直接运行,比如使用易语言,python 等语言,将应用打包成 exe,然后跑在 window 系统上。
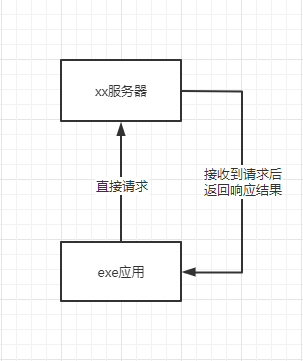
这样的应用会有以下几点缺陷:
-
易破解:由于你的大部分核心逻辑最终都会进行编译打包成 exe,如果会些破解技术,恰好你不做任何防护手段,要破解你的程序非常容易。所以也就为什么很多 exe 程序(尤其是易语言)会带有
.vmp.exe后缀也就是 vmp 加壳,让程序很难被分析与破解。并且我就可以开启系统抓包,就可以看到应用程序模拟发送的请求数据包是什么。 -
不易跨平台:大多数的协议复现都是 exe 桌面应用程序,虽然也有安卓,但一般比较少。对于非 windows 用户或者说手头不方便用电脑的用户就很难体验到,并且还要特意安装一个应用,应用程序�更新也需要重新安装。
其实我说的这些,也算是绝大部分都是桌面应用程序的一个“通病”,但也不是没有优点,这在后面介绍后端应用开发的会做一个比较。
后端应用开发
另一种方式就是我自行搭建一个后端服务,然后将我要模拟的请求封装成一个接口供外部调用。只要我的这个后端服务允许跨域请求,那么我在浏览器或者在桌面端应用都能调用该接口。这样做调用者根本不可能知到你这个接口返回的数据的核心代码(除非他能渗透你的服务器)。
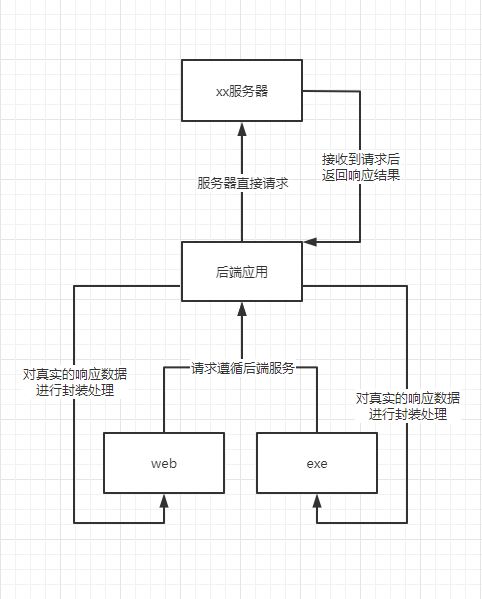
别人像要复现一个相同的协议请求的话,就必须自行抓包分析原站点的数据。而原站点可能做了一定的防护手段,例如验证码 浏览器指纹等风控手段。对于一般人而言,非常难破解。但是假设你能复现该请求的话,又非常不想让别人复现,那么自行搭建一个后端服务封装是最好的手段。而在此基础上,你可以做一些限制,比如接口封装,调用收费等等。
这里我就不细说太多了,但也不是说没有缺点,甚至可以说这个缺点不比桌面端应用好到哪里:
-
部署后端服务:由于搭建了一个后端服务,那么就需要将后端服务部署到服务器上,部署后端服务是小事(但其实也很麻烦,有些写协议复现也不一定会后端开发),但是需要考虑用户的访问量,可能并发量大,那么请求就可能会阻塞导致响应速度变慢。
-
请求限制:从上流程图也不难看出,由于��后端应用是部署在自己的服务器上,同时需要承载多个接口请求,然后模拟的请求都是由自己后端应用服务器发送的,这和桌面端应用不同。桌面端模拟的请求发送是用户自己的电脑,即用户自己电脑的 ip 地址,而后端应用服务器是服务器的 ip。一旦发送的请求多了,必然是会限制请求的,说白了就是将 ip 黑了,无法访问。要解决的最有效的办法就是换 ip,使用一些 ip 代理服务商,在请求 xx 服务器的时候使用动态 ip 来请求,检测被黑 ip 之后就换另一个 ip 来请求,但是这样就需要额外支付一些 ip 的费用。
如果你需要跨平台(web 端,桌面端,手机端)并且想要保护好你的模拟请求的代码,那么就要考虑选择后端应用开发方案。
像我一开始所介绍的小区开门网页版就是属于这一范围,这里就不再赘述其实现过程了。
前端应用开发/反向代理(可行)
假设你手头已经有了某个网站的大部分协议复现的代码接口,但是不想搭建一个后端应用,却想要在前端中使用。有没有解决方案,这也是有的。
一种就是通过浏览器插件来允许任何请求跨域,或者本地开启 http 响应替换,将允许跨域的协议头加到响应中。但这些手段都需要使用者有一定的开发能力,对于普通用户而言就无能为力。
目前绝大多数的网站应该都属于前后端分离的形式,后端只提供服务与接口的,提供的接口一般都带有 /api/ 或 /v1/ 等请求前缀。那么就可以将前端的请求,通过反向代理,转发到原应用服务器。
反向代理其实也需要服务器,但是和后端应用相比,只需要配置一个 nginx,例如
location /api/ {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://要转发的服务器域名/api/;
index index.html index.htm index.jsp;
}
举个例子,原后端应用通过 http://target.com/api/user/me 来获取目标服务器用户信息,如果我的前端应用 http://example.com 想要请求该接口必然会有跨域限制。但是通过反向代理,我的前端应用可以请求 http://example.com/api/user/methods,nginx 会判断 url 是否为 /api/ 前缀,将请求转发给 http://target.com/API。说白了请求 http://example.com/api/user/me 就是在请求 http://target.com/api,同时还不会触发跨域,反向代理也是解决跨域的常用方法之一。
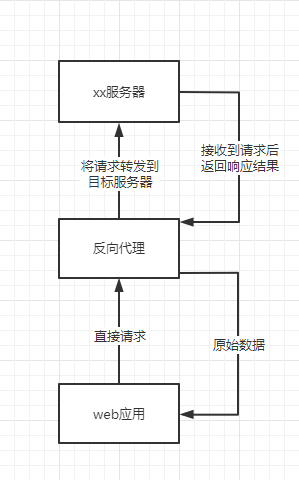
由于请求还是通过服务器发送的,所以后端应用开发有的限制,在反向代理也同样是有的。还有就是对于限制设备请求的服务器,使用这种方案就不行。。。
同时这种开发方案对于多域名的应用来说可能就不是那么友好,因为就需要配置比较多的反向代理,同时只是将接口转发,接口的定制化就不是那么好。只不过你可以原封不动的将原有的请求迁移到前端,假设有了某个网站的大部分协议复现的代码接口,那么这样迁移将会特别方便。
方案选择
最终选择那种开发方式还是取决对应的应用场景,没有绝对的方案,具体考虑哪种方案是需要考虑用户,代码安全,请求量,是否维护来考量了。
写到这,可能对大多数人而言还是不懂,也很正常,因为这些内容都不算属于传统开发的范畴,甚至可以说是做 hui 产的利器。
全栈框架
我非常希望使用到浏览器的跨平台性,即多端运行,用户的设备只需要有一个浏览器能打开网页就能体验到。(这其实也算是我为什么学 web 开发的初衷了)
但是在一开始所介绍的小区开门应用中,这样的开发体验其实并不友好。因为我既要编写前端应用还要编写后端服务,相当于两个项目。同时部署应用和传统部署没有特别大的区别,都需要一台服务器,很多时候都是浪费在部署上。
而全栈框架可以算是后端应用开发和前端应用开发结合。能很好的解决上述存在的问题,并且也易于部署,下面我会细细道来。
这里我选用的 Nuxt 框架,这是一个基于 Vue 前端框架实现的服务端渲染框架,羊了个羊刷次数网页版就是基于 Nuxt3 框架来开发的,并且使用 vercel 来进行部署。我手头还写过一个项目 api-service。
首先在全栈框架,是有对应的后端服务引擎。像 Nuxt 使用的是 Nitro,而 Next.js 使用的是 koa。都提供了后端服务 API 的解决方案,同时这些都是服务都算是 serverless function(无服务函数),所以在编写与调用非常方便。
此外基于 Netlify 和 Vercel 这些 serverless development 平台,可以非常方便的部署全栈框架。同时内置 CI/CD,只需要提交 git commit 就能实现自动构建自动部署。
最主要是的我恰好使用 Node.js 来做爬虫与 api 接口,因此后端复现接口也使用 js 来实现。
为此我特意编写了一个 Protocol 协议复现模板 ,这里我就不在过多介绍该模板。
总结
协议复现能写非常多的程序,因为协议复现的大多数案例都是基于已有的应用服务上去实现的,而很多人的日常生活都使用这些已有的服务上。有些已有的服务可能对于一些人而言,体验不好,或者是有其他限制。因此就有人对这些已有的服务来进行“扩展”,来实现自己所定制化的需求。